
ConcurrentHashMap in java
ConcurrentHashMap was introduced in Java 5 with other concurrency utils such as CountDownLatch, CyclicBarrier and BlockingQueue.
ConcurrentHashMap in java is very similar to HashTable but it provides better concurrency level.
You might know , you can synchonize HashMap using Collections.synchronizedMap(Map). So what is difference between ConcurrentHashMap and Collections.synchronizedMap(Map)In case of Collections.synchronizedMap(Map), it locks whole HashTable object but in ConcurrentHashMap, it locks only part of it. You will understand it in later part.
Another difference is that ConcurrentHashMap will not throw ConcurrentModification exception if we try to modify ConcurrentHashMap while iterating it.


Getting value from ConcurrentHashMap is straight forward.
ConcurrentHashMap in java is very similar to HashTable but it provides better concurrency level.
You might know , you can synchonize HashMap using Collections.synchronizedMap(Map). So what is difference between ConcurrentHashMap and Collections.synchronizedMap(Map)In case of Collections.synchronizedMap(Map), it locks whole HashTable object but in ConcurrentHashMap, it locks only part of it. You will understand it in later part.
Another difference is that ConcurrentHashMap will not throw ConcurrentModification exception if we try to modify ConcurrentHashMap while iterating it.
Let’s take a very simple example. I have a Country class, we are going to use Country class object as key and its capital name(string) as value. Below example will help you to understand, how these key value pair will be stored in ConcurrentHashMap.
ConcurrentHashMap in java example:
1. Country.java
2. ConcurrentHashMapStructure.java(main class)
Now put debug point at line 23 and right click on project->debug as-> java application. Program will stop execution at line 23 then right click on countryCapitalMap then select watch.You will be able to see structure as below.
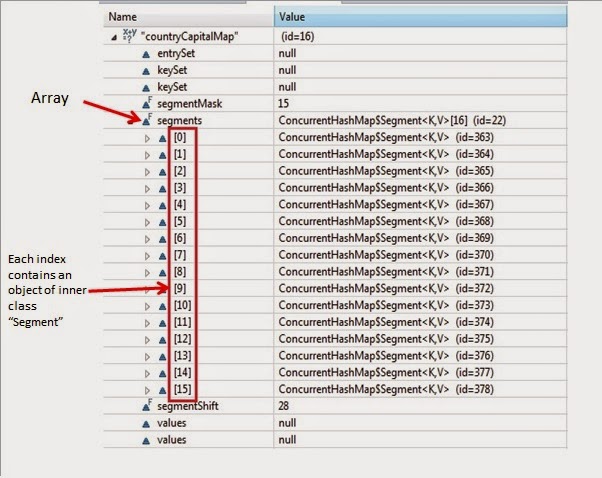
Now From above diagram, you can observe following points
- There is an Segment[] array called segments which has size 16.
- It has two more variable called segmentShift and segmentMask.
- This segments stores Segment class’s object. ConcurrentHashMap class has a inner class called Segment
Now lets expand segment object present at index 3.
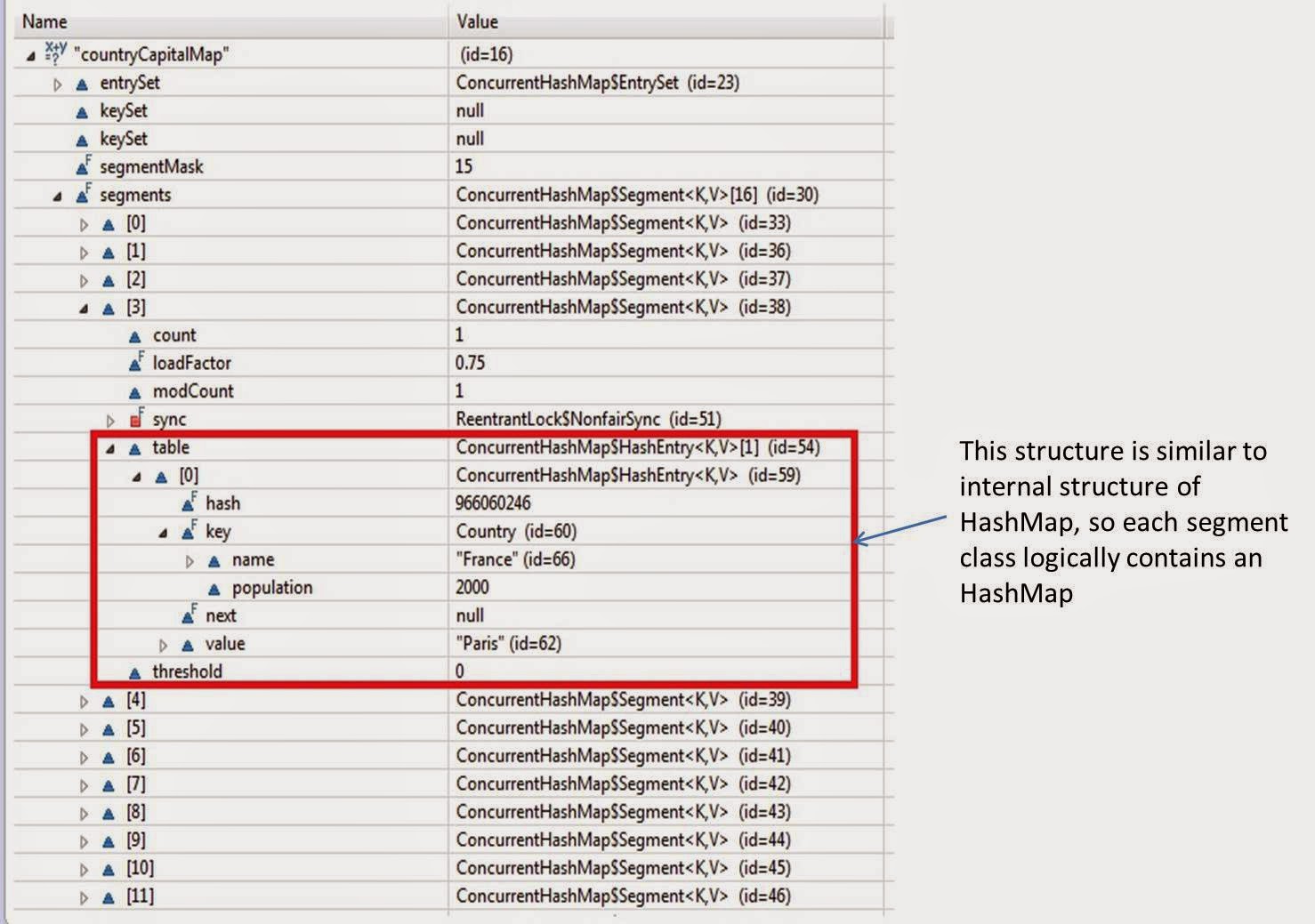
In above diagram, you can see each Segment class contains logically an HashMap.
Here size of table[](Array of HashEntry class) : 2ˆk >= (capacity/number of segments)
It stores a key value pair in a class called HashEntry which is similar to Entry class in HashMap.
Here size of table[](Array of HashEntry class) : 2ˆk >= (capacity/number of segments)
It stores a key value pair in a class called HashEntry which is similar to Entry class in HashMap.
When we say, ConcurrentHashMap locks only part of it.It actually locks a Segment. So if two threads are writing different segments in same ConcurrentHashMap, it allows write operation without any conflicts.
So Segments are only for write operations. In case of read operation, it allows full concurrency and provides most recently updated value using volatile variables.
Now as you understood internal structure of ConcurrentHashMap, it will be easier for you to understand put function.
Now as you understood internal structure of ConcurrentHashMap, it will be easier for you to understand put function.
Concept of ConcurrencyLevel:
While creating a ConcurrentHashMap object, you can pass ConcurrencyLevel in the constructor. ConcurrencyLevel defines”Estimated number of threads going to write to the ConcurrentHashMap”. Default ConcurrencyLevel is 16. That is why, we got 16 Segments objects in above created ConcurrentHashMap.
Actual number of Segment will be equal to next power of two defined in ConcurrencyLevel.
For example:
Lets say you have defined ConcurrencyLevel as 5, so 8 Segments object will be created as 8=2^3 so 3 higher bits of Key will be used to find index of the segment
Another example: You want 10 threads should be able to access ConcurrentHashMap concurrently, so you will define ConcurrencyLevel as 10 , So 16 Segments will be created as 16=2^4 so 4 higher bits of Key will be used to find index of the segment
Actual number of Segment will be equal to next power of two defined in ConcurrencyLevel.
For example:
Lets say you have defined ConcurrencyLevel as 5, so 8 Segments object will be created as 8=2^3 so 3 higher bits of Key will be used to find index of the segment
Another example: You want 10 threads should be able to access ConcurrentHashMap concurrently, so you will define ConcurrencyLevel as 10 , So 16 Segments will be created as 16=2^4 so 4 higher bits of Key will be used to find index of the segment
put Entry:
Code for putEntry is as follows:
When we add any key value pair to ConcurrentHashMap, following steps take place:
- In ConcurrentHashMap, key can not be null. Key’s hashCode method is used to calculate hash code
- Key ‘s HashCode method may be poorly written, so java developers have added one more method hash(Similar to HashMap) , another hash() function is applied and hashcode is calculated.
- Now we need to find index of segment first, For finding a segment for given key, above SegmentFor method is used.
- After getting Segment, we use segment’s put method.While putting key value pair in Segment, it acquires lock, so no other thread can enter in this block and then it finds index in HashEntry array using hash &(tab.length-1).
- If you closely observe, Segment’s put method is similar to HashMap’s put method.
putIfAbsent:
You want to put element in ConcurrentHashMap only when if it does not have Key already otherwise return old value. This can be written as:
Above operation is atomic if you use putIfAbsent method. This may be required behaviour. Let’s understand with help of an example:
- Thread 1 is putting value in ConcurrentHashMap.
- At same time, Thread 2 is trying to read(get) value from ConcurrentHashMap and it may return null So it may override whatever thread 1 has put in ConcurrentHashMap.
Above behavior may not be required so ConcurrentHashMap has putIfAbsent method.
get Entry:
Getting value from ConcurrentHashMap is straight forward.
- Calculate hash using key ‘s Hashcode
- Use segmentFor to get index of Segment.
- Use Segment’s get function to get value corresponding to the key.
- If it does not find value in ConcurrentHashMap ,it locks the Segment and tries again to get the value.
Best Practice:
We should not use default constructor of ConcurrentHashMap if we require low level of Concurrency level as default ConcurrencyLevel is 16 and it will create 16 Segments by default.
We should use fully parameterized constructor:
ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel)
In above constructor, initialCapacity and loadFactor is same as HashMap and concurrencyLevel is same as we have defined above.
So if you require only two threads that can write concurrently, you may initialise ConcurrentHashMap as:
ConcurrentHashMap will perform much better if you have few write threads and large number of read threads.
That’s all aboutConcurrentHashMap in java.



